
Let’s get to know the Intel technology implemented in SmartEverything, taking an overall look at the concepts at the base of it.
You are probably familiar with the Arduino-like prototyping board series called SmartEverything, developed in partnership with Arrow Electronics, something we have talked about at length in last February’s issue; that time, while listing the various boards, we mentioned the upcoming ability of the Panther board, based on a recently implemented technology called Pattern Matching Technology.
This machine learning technology simplifies, for instance, the recognition of gestures, sounds, vibrations and applications connected to it; it is therefore aimed to the realization of solutions where you need to acquire environmental parameters or interact with a human, instead of acquiring physical measurements. In the Panther board, data connection takes place over a traditional Wi-Fi link, while interaction with physical quantities is managed by Intel technology, in fact the Panther is equipped with a Intel QuarkTM SE C1000 core in order to implement it; we remind you that Intel Quark processors can be found on various mobile devices and industrial boards and also on the recently discontinued Galileo board, an Arduino-like board introduced some years ago by Intel, aimed to the makers.

The Panther can also act as Wi-Fi Gateway for the data link on the sensors (which can be connected to a dedicated unit for data gathering) and can count on the support of IBM Bluemix Cloud services on Semioty APP.
After describing the board in the above-mentioned February issue, now it’s time to take an in-depth look to Intel Pattern Matching Technology, which is an implementation of Pattern Recognition.
The term Pattern Recognition describes a sub-area of automated learning (better known as Machine Learning) executed by a microprocessor system; in certain situations and applications, Pattern Recognition and Machine Learning might seem synonymous.
Pattern Recognition is the identification and analysis of repeated patterns and models within raw data, in order to determine their classification. Most of the research in this field follows the following methods:
- supervised learning; in this case, data gathered is “labeled” and catalogued by specific algorithms generated from previous experiences;
- unsupervised learning; in this case data is not “labeled” and must be elaborated by specific algorithms that are used in order to discover previous known models.
Broadly speaking, terms Pattern Recognition, Machine Learning, Data Mining and Knowledge Discovery in Database (KDD) are tightly connected and it is difficult to clearly distinguish them, since their scope of definition is subject to ample overlapping.
In fact, the term Machine Learning generally defines the method of supervised learning and is a common term for all the methods, originated from the concepts of artificial intelligence; on the other hand, KDD and Data Mining are more focused on unsupervised methods.
In the context of Pattern Recognition applications, it can be more interesting to formalize, explain and visualize models, while Machine Learning applications are traditionally focused on maximizing recognizing rates (success rate of recognition). Anyway, all these categories have remarkably evolved since their origin, becoming branches of Artificial Intelligence, Engineering and Statistics, and they became more and more similar one another, by integrating each other’s developments and ideas.
Historically, the term Pattern Recognition comes from its applications in engineering, but it’s currently positioned in the context of the artificial vision; in fact, one of the main world conference on the subject is CVPR, the Computer Vision e Pattern Recognition conference (more info available on the event’s website.

Another definition of Machine Learning identifies Pattern Recognition as the act of assigning a label to a specific piece of data inputted into the system. Some examples of Pattern Recognition are:
- classification aimed at assigning each inputted value to a specific group of classes (EG determining if an email is “spam” or “non spam”);
- regression assigning a real-valued output for each inputted data;
- sequence label assigning the class to each member of a value sequence (for instance, part of vocal tagging assigning a part of speech to each word in an input sentence);
- analysis assigning a parsing tree to an input sentence, describing the syntactic structure of the sentence.
As described earlier, Pattern Recognition if generally classified based on the type of procedure and learning used to generate the output value.
Supervised learning requires a dataset to be fed with a training set, constituted by a group of instances which have been properly labeled with correct corresponding output. The learning procedure, therefore, generates a model that tries to satisfy to two goals that are sometimes in contrast:
- executing input recognition in the best possible way based on the training set;
- generate new input data in the best possible way in order to refine the recognizing model.
On the other hand, unsupervised learning involves training data there are not “manually” labeled, and tries to find models related to those data that can be then used in determining the correct output value for the new data instances.
A combination of the two learning types, previously explored, it is the semi-supervised learning, employing a combination of labeled and non-labeled data (typically small group of labeled data combined with huge quantities of unmarked data).
Pattern Recognition algorithms, therefore, aim to output a statistically reasonable response, analyzing input data (also taken into account their statistical variation) and trying to find the “most probable” correspondence based on the value of the same input data. This collaboration model opposes to Pattern Matching algorithms which look for exact correspondences in preexistent models in correlation to what is inputted in the system.
Therefore, in Machine Learning, Pattern Recognition means assigning a label to determinate output value. In Statistics, discrimination analysis was introduced to this purpose in 1936.
Pattern Recognition algorithms generally have the goal to provide a reasonable response to all possible inputs and matching input data with higher success probabilities, factoring in their statistical variation. This model is in opposition to pattern matching algorithms, which look for exact correspondences in preexistent models. A common example of a pattern matching algorithm is a correspondence of regular expressions, which looks for models of a specific type in text data and it’s included in the search feature of many text editors and word processors. Contrary to Pattern Recognition, Pattern Matching is not generally regarded as a type of Machine Learning, although Pattern Matching algorithms (especially with quite generic, carefully customizable models) can sometimes provide an output which is similar, in terms of quality, to those provided by Pattern Recognition algorithms.
Note that, in case of unsupervised learning, there is no training data; in other words, data to be labeled is training data.
Note that, sometimes, different terms are used to describe procedures corresponding to supervised and unsupervised learning for the same kind of output. For instance, the unsupervised equivalent of classification is normally known as clustering, and is this based on tasks being commonly considered as implying exchange of training data and grouping of input data in clusters based on some intrinsic similarity measurement (e.g. instances distance, considered as vectors in a multidimensional vector space), instead of assigning each input instance to a group of predefined classes.
The portion of input data for which an output value is generated is called instance. The instance is described by a characteristic vector, which together compose a description of all the known characteristics of the instance; said functional vectors can be seen as definition points in the appropriate multidimensional space, and methods to manipulate factors and vector spaces can be applied to them, such as calculation of scanner product or the angle between two vectors.
Typically, characteristics can be:
- categorical, also known as nominal, i.e. constituted by a group of unsorted elements, e.g. a “male” or “female” genre, or a “A”, “B”, “AB” or “0“ blood type;
- ordinal, composed of a series of sorted articles, such as “big”, “medium”, “Small”;
- integer values (e.g., count of the number of instances of a particular word in an email);
- real values: for instance, measurement of arterial blood pressure.
Often times, categorical and ordinal data are grouped together; same goes for integer values and real values. Besides, many algorithms only work in terms of category and acquire real values or integer values to be grouped discreetly (e.g., less than 5, between 5 and 10, or more than 10).
Many recognition algorithms of common patterns are of probabilistic nature, in that they use statistical interference in order to find the best label for a specific instance. Unlike other algorithms which simply provide the “best” label, often times probabilistic algorithms also provide the probability of the instance, described by a label, in the output. Besides, many probabilistic algorithms provide a least of the best “n” labels with related probability, for a value of N, instead of a single labeled regarded as the best one. When the number of possible labels is sufficiently small (for instance, in case of classification), N can be set to output probability of all possible labels. Probabilistic algorithms have many advantages compared to non-probabilistic algorithms, described below.
- They provide a reliable output value associated to their selection. Note that some of the rhythms might provide reliable output values however, in general terms, only in case of probabilistic algorithms those values are mathematically based on the statistical theory. Reliable non-probabilistic values can generally have not a specific meaning and are only used to compare them with other reliable output values from the same algorithms; as a consequence, they can be ignored when the reliability of a certain output is too low.
- Due to output probabilities, recognizing algorithms of probabilistic models can be incorporated in broader machine learning tasks in a more efficient way, in order to partially or completely avoid the issue of error propagation.
Intel technology
Now, let’s transfer the above-mentioned concepts to the Intel word, by talking about Pattern Matching according to the Santa Clara Company. A SoC (System on Chip) with advanced functionalities allowing to apply the concepts of pattern recognition and pattern matching in industrial environments and IoT has been available in the Intel product catalog for quite some time: it’s the Quark SE, which by the way is a quite used in performing SoC.

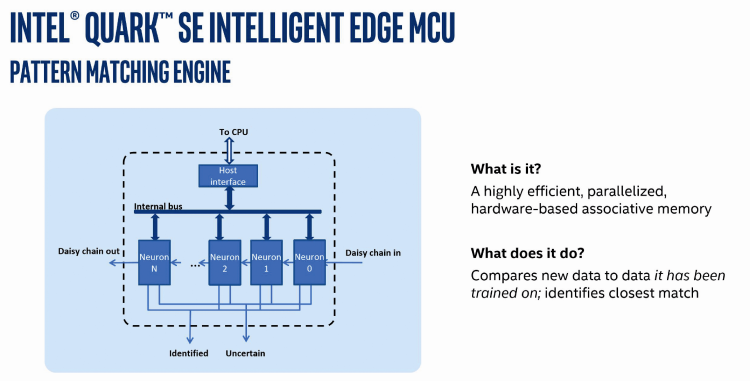
Figure allows understanding the operational flow provided by Intel technology that the project developer must follow in order to develop Pattern Matching applications. We can identify the following blocks in this flow:
- Edge Device; it is the component itself (Intel Quark SE System on Chip), which takes care of gathering input info and classify it (through the Sensor Hub block) and then transfer it to the Pattern Matching Engine block. Intel Quark SE Intelligent Edge MCU is some kind of parallel elaboration hardware associative memory and therefore a high-efficiency one.
- The Pattern Matching Engine block allows, after setting up and training the Neural Network, to execute the effective Pattern Matching on the sampled input data; this “engine” can be connected to Server (via Cloud) to pass all classification data to the application tased with the creation of the recognition models used for creating the neural network.
- The Server with a Cloud Application block uses the information classified by the Quark’s Pattern Matching Engine to create the model of a neural network (and subsequent refinements of said model). This neural network will allow the Pattern Matching engine to correctly identify inputted patterns. For modeling and creating the neural network, the server application use some specific algorithms.
The Intel Quark SE microcontroller includes a sophisticated Pattern Matching technology that allows you to correctly learn, through shape recognition, and differentiate response events. Having an onboard decisional capacity allows supplying a bona fide real-time response, as requested in industrial environment, for controlling energy consumption and the triggering an action in the event of an anomaly.
It can also reduce costs through reduction of gateways necessary for managing onboard data.
The Intel Quark SE’s microcontroller integrates a sensor hub managing multiple sensors and allowing to support multiple peripherals. It also allows making CPU go in sleep mode, until the sensor controller wakes it up based on the program, with ultralow energy consumption as a result.
The Intel Quark SE’s microcontroller extends the solid Intel safety up to the device with hardware-based and software-based characteristics to protect data in each end-point.
The Intel Quark SE’s microcontroller offers integrated intelligence for real-world applications. It is interoperable with other systems based on Intel components, therefore simplifying integration of onboard products in end-to-end IoT architectures. Moreover, it can be managed at device level, therefore reducing the need for big gateways. The Intel Quark SE’s microcontroller simplifies the design and reduces the bill of materials (BOM) therefore minimizing the quantity of external components needed on the platform. The integrated development environment Intel System Studio is included in every Intel microcontroller. This allows reusing the software for realizing scalable applications.

Intel Quark SE SoC is available in a 144-pin BGA case of around 10 x 10 mm and it just classified as industrial grade (-40°C to +85°C), it has a single voltage power ranging from 1.8 V and 3.3 V, simplifying its use.

