
Let’s use a new Real Time Clock by Microchip, by making it available on a shield for two prototyping boards. First Installment.
Many applications require an hourly information, that is locally obtained by means of circuits that are named RTCs (Real Time Clock) or RTCCs (Real Time Clock Calendar); among them are clock radios, time and access control systems, time switches, etc. The clock function may be implemented in a simple way, thanks to integrated circuits such as the DS1307 (which we used many times) or the more recent MCP79410 by Microchip; with the latter we created a multi-purpose shield that may be applied to Arduino and Raspberry Pi boards. Let’s start by describing the integrated circuit by Microchip and the library that has been developed for the Arduino ecosystem. In the second installment we will see how to use it along with Raspberry Pi.
THE INTEGRATED CIRCUIT, MCP79410
The RTCC belongs to a family of integrated circuits that includes MCP79411 and MCP79412 as well; the last two have memorized an univocal MAC address for the Ethernet applications. More exactly, the MCP79411 uses a MAC address in the EUI-48 format, while the MCP79412 has it in the EUI-64 format. The EUI acronym stands for Extended Unique Identifier and it may be used in order to assign a 48 or a 64 bit univocal address in the networking applications. Since we do not have to develop a networking application, we used the MCP79410, that has the following features available:
- configuration of hours, minutes and seconds, both in the 24h and in the 12h (AM/PM) format;
- configuration of day, month, year, and day of the week;
- automatic management of leap years;
- 32,768 Hz oscillator;
- digital internal calibration/regulation, with a ±1ppm resolution (maximum range ±129ppm);
- two programmable alarms;
- TimeStamp both on power-up and on power-down;
- 64 Byte buffered SRAM memory;
- 128 Byte EEPROM memory, with the possibility of page writes, 8 bytes at a time;
- 8 Byte protected EEPROM memory: in order to write it (it is possible, one single bit at a time), it is needed to execute an unlock sequence;
- I2C communication interface, up to 400 kHz.
Figure shows the internal block diagram of the MCP79410 integrated circuit, in which it is possible to see the logical blocks that form the device. The I2C interface considers two hardware addresses, one for the management of the RTCC and the other one for the management of the EEPROM memory.

Figure shows two possible control bytes that contain the hardware address for the RTCC or the EEPROM section. The first one 0b1101111x as a value: in the place of the “x” there will be “0” or “1”, depending on the operation we want to execute (“0” – writing; “1” – reading). On the other hand, the second one will be 0b1010111x, with “x” assuming the above described values.

Figure shows the register and memory mapping: the addresses from 0x00 to 0x1F contain the configuration registers as for time and date, in addition to the registers for the configuration of the alarms 0 and 1. The section is ended with the registers for the management of the TimeStamp at the power-up and at the power-down. From address 0x20 to 0x5F the buffered SRAM memory is mapped. The remaining addresses, up to 0xFF, have not been used.
What has just been said refers to the hardware address 0b1101111x. On the other hand, the EEPROM is mapped starting from the address 0x00 and up to 0x7F, that are followed by a series of addresses that have not been used (from 0x80 to 0xEF); from address 0xF0 and up to 0xF7 the protected EEPROM memory is located: it may be programmed, only one byte at a time, and only after having carried out the unlock sequence. Lastly, at the 0xFF address the STATUS register is located. What has just been said refers to the hardware address 0b1010111x.

CIRCUIT DIAGRAM
Thanks to the MCP79410 integrated circuit, we created a shield that may be applied both to an Arduino Uno R3 board and to a Raspberry Pi 2.0/3.0/B+ one. The electronic parts and an appropriate programming of Arduino (or of Raspberry Pi) allow to fully configure the MCP 79410, above all in its functions concerning the management of the alarms needed for the switching on and off of the board connected to the shield. All of the functions that are needed in order to manage the integrated circuit have been collected in the libraries, both for Arduino and Raspberry Pi.
Let’s begin the study of the circuit diagram, starting from the CN1 connector (microUSB) which brings the +5Vcc stabilized power to the Q1 MOSFET (at the P channel), that is used as an hardware switch. The Q1 is in interdiction, as long as the gate is not shortcircuited to ground, as soon as the VGS exceeds the threshold value opening the MOSFET’s channel, thus it transfers the power from the source to the drain. The “new” power source is named +5VRA. There are two possibilities in order to bring the Q1 gate to ground: 1) the MCP79410, via the “MFP” open-collector output, acts on the two transistors, Q2 and Q3; 2) the “ForceOn” command line polarizes the Q6 transistor that brings the Q1 gate to ground.
Let’s return to the MFP output line, of which figure shows the logic that is internal to the MCP79410: it may be configured in order to operate as a general output, or to supply a logic state when one of the two configurable alarms occurs, as well as the clock frequency
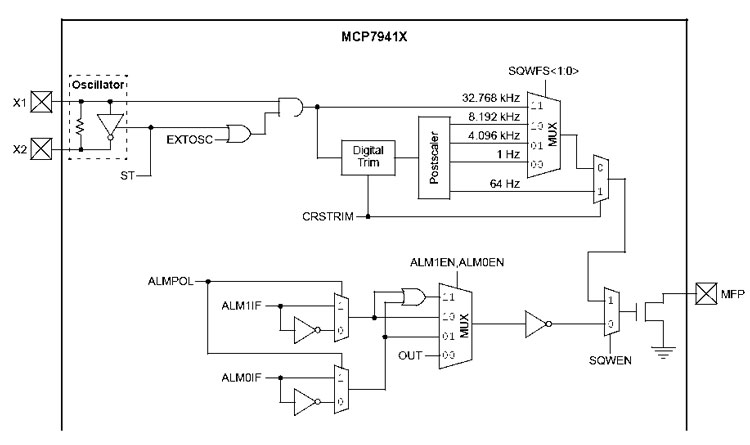
. If you want that the output returns the oscillator’s clock frequency or one of the derived frequencies, you need to set the “SQWEN” bit of the “CONTROL” register at logic “1”. In order to decide which frequency should be returned on the output, the “SQWFS0” and “SQWFS1” bits need to be configured: they are still in the “CONTROL” register. The possible frequencies are 1, 4,096, 8,192 e 32,768 Hz (please refer to the data-sheet for the details).
If we wanted that MFP becomes a general ouput, we need to set the “SQWEN” bit at logic level zero and to disable both alarms. On the other hand, our case considers that the MFP is driven by the alarms 0 and 1, therefore “SQWEN” must be set to zero and the two bits, “ALM0EN” and “ALM1EN” must both (or at least one of them) take a high logic value. Since the MFP is an open-collector output, it may be intended as an interrupt line, indicating that one or both alarms have been triggered, as a consequence of reaching the conditions set. Later on, we will see how to configure and take advantage of the two alarms available. In conclusion, the MFP may be brought to a microcontroller so to indicate that one or both of the configured alarms have been activated, thus avoiding to write polling code concerning the state of the two alarms. Moreover, it is possible to define if the MFP is active at a logic level 0 or 1; for the purpose you have to act on the “ALMPOL” bit in the “ALM0WKDAY” and “ALM1WKDAY” registers. In our application the output must be active at a high level.
Table 1 shows the behaviour of the MFP, on the basis of the configuration of the ALMPOL bit and of the state of the interrupt flag of the x alarm: when ALMPOL is set to “1”, the MFP output follows the state of the interrupt flag of the n alarm, in the case of just one active alarm; if both alarms are active and configured, the MFP line follows the behaviour of the logical OR of the two interrupt flags of the alarms 0 and 1. On the other hand, if the ALMPOL bit is set to 0, the MFP is the negation of the interrupt flag of the n alarm set (only one alarm being set) or it follows the behaviour of the logic NAND of the two interrupt flags of the alarms 0 and 1.
Table1

The MCP79410 integrated circuit is powered via the +5VRA voltage, which is also brought to the Arduino Uno R3 board and to the Raspberry Pi board. The MCP79410 also has a VBAT input to which a buffer battery is connected: it keeps it powered in the case a power source is lacking. During the battery operation, only a part of the integrated circuit remains active: in particular the RTCC (management of time and date) block and the 64 Bytes of the SRAM. Moreover the MFP line remains active, if it has been configured so to work in combination with the alarms 0 and 1, otherwise it will be disabled.

The functions for managing time and date require a clock frequency of 32,768 Hz, that is obtained by connecting a crystal to the pins X1 and X2. Finally the I2C communication interface is brought both to Arduino and Raspberry Pi by means of the corresponding connection; please notice that the I2C bus requires a bidirectional level translator for the interconnection with Raspberry Pi, since its I/O lines work on a +3V3 logic level. This is obtained by taking advantage of the Q4 and Q5 MOSFETs, that operate as in figure: such a bidirectional level translator also works for a SPI or whatever bidirectional line and in it, each section is powered with a different voltage level; in our case, +3V3 for the electronics of the Raspberry Pi board, +5V for the MCP79410 integrated circuit. The low voltage section, on the left, considers two pull-up resistors that are connected to the MOSFET’s source, as for the SDA and SCL lines, while the gate is directly connected to the lowest power supply voltage: +3V3, in our case. The high voltage section also considers two pull-up resistors, that are connected to the MOSFET’s drain. The MOSFET used for both lines is an enhancement mode, N-channel one, with the body terminal internally connected to the source (the diode that connects the body terminal to the drain – thus creating a NP junction – must be integrated); the ones we used are the BSS123s. Let’s see in detail the three operating states, with the premise that what is being said is not true for both lines:
- No peripheral imposes a low voltage level on the line, therefore on the 3.3V side the pull-up resistor imposes the logic 1 and, as a consequence, the Vgs does not exceed the MOSFET’s threshold, since the Vg and Vs have the same voltage, therefore the MOSFET does not start to conduct; on the 5V side, the line is found at a high logic level, imposed by the corresponding pull-up resistor;
- the 3.3V peripheral imposes a low voltage level on the line, therefore the MOSFET’s source goes to a low logic level; the Vgs exceeds the threshold and makes the MOSFET start to conduct; with the MOSFET conducting, the low logic level is also imposed in the 5V section;
- The high voltage 5v peripheral imposes a low voltage level on the line; on the low voltage line the pull-up resistor imposes a high logic level and therefore makes the diode inside the MOSFET start to conduct (the VS decreases and consequently the VGS exceeds the threshold and makes the MOSFET start to conduct, therefore at this point the two sections have the same voltage level on the line).

The maximum tolerable frequency on the I2C is 400 kHz.
The P1, P2 and P3 buttons, connected both to Arduino and to Raspberry Pi, are used during the configuration phase regarding the RTC and the alarms. In order to ease the development stages, some trigger signals have been prearranged: three of them are brought to the CN2 connector for Arduino, and two for Raspberry Pi, also brought to the CN2 connector. The trigger signals are in common between the two boards, since they cannot be connected to the shield at the same time. Still from the two boards, the “ForceOn” signal starts: it is needed in order to keep the Q1 electronic switch in the ON state. The LD4 (connected to Arduino) and the LD5 (connected to Raspberry Pi) LEDs – used during the MCP79410’s configuration phase – complete the circuit diagrams. Lastly, LD1 indicates the presence of the main power source coming from the microUSB; on the other hand, LD2 indicates that the +5VRA secondary power source is found. LD3 indicates the presence of the +3V3 power source.
A last note concerning the J1 jumper, that is needed in order to bypass Q1: it is needed during the MCP79410 configuration, especially if Raspberry Pi is connected. Actually, Arduino is already self-powered by means of the USB connector that is connected to the PC, for the programming via Arduino IDE.
BOM
R1: 1,2 kohm 1% (0603)
R2: 1,2 kohm 1% (0603)
R3: 1,2 kohm 1% (0603)
R4: 22 kohm 1% (0603)
R5: 2,2 kohm 1% (0603)
R6: 2,2 kohm 1% (0603)
R7: 2,2 kohm 1% (0603)
R8: 10 kohm 1% (0603)
R9: 4,7 kohm 1% (0603)
R10: 680 ohm 1% (0603)
R11: 2,2 kohm 1% (0603)
R12: 680 ohm 1% (0603)
R13: 2,2 kohm 1% (0603)
R14: 680 ohm 1% (0603)
R15: 3,3 kohm 1% (0603)
R16: 10 kohm 1% (0603)
R17: 4,7 kohm 1% (0603)
R18: 1 kohm 1% (0603)
R19: 1 kohm 1% (0603)
R20: 1 kohm 1% (0603)
C1: 10 µF ceramic (0603)
C2. 10 µF ceramic (0603)
C3: 100 nF ceramic (0603)
C4: 10 pF ceramic (0603)
C5: 10 pF ceramic (0603)
C6: –
C7: 10 µF ceramic (0603)
C8: 10 µF ceramic (0603)
C9: 10 µF ceramic (0603)
C10: 10 µF ceramic (0603)
LD1: LED red (0805)
LD2: LED yellow (0805)
LD3: LED green (0805)
LD4: LED green (0805)
LD5: LED green (0805)
P1: Microswitch
P2: Microswitch
P3: Microswitch
Q1: SPD50P03LG
Q2: BC817
Q3: BC817
Q4: BSS123
Q5: BSS123
Q6: BC817
CN1: Connector micro-USB
CN2: Strip male 4 vie
J1: Strip male 3 vie
BT1: battery case CR2032
U1: MCP79410-I/SN
Y1: Quartz 32768 Hz
Various:
– Battery CR2032
– Jumper
– Strip M/F 6 vie
– Strip M/F 8 vie (2 pz.)
– Strip M/F 10 vie
– PCB S1254
LIBRARY FOR MCP79410
The library allows the configuration and management of the MCP79410 integrated circuit and it is divided in three files; the first one contains the functions developed for the occasion and has the .cpp file extension (we named it MCP79410.cpp). The second one has the .h file extension and contains the function declarations of the previous one, plus all the variables and data structures that are needed (MCP79410.h). The third one (keywords.txt) is a text file containing the keywords of the public functions to be used in Arduino sketches. All of them must be grouped under a common folder (inside of Arduino IDE’s installation folder), named MCP79410. In this way, the library will appear in Arduino IDE, under the menu entry Sketch>Include Library.
Therefore, and supposing that the Arduino IDE has been installed under C:\Program Files (x86)\Arduino our library will have to be saved in the following path: C:\Program Files (x86)\Arduino\libraries\MCP79410. In addition to the library files, it is customary to add a folder with some sample sketches: in our case we created the Examples MCP79410_SAdvancedSettings subfolder, in which the files of our sketch are found, they allow us to configure the MCP79410’s registers.
Let’s start to broadly describe the MCP79410.h file that, as previously stated, contains the definitions of all the used functions and the declaration of the variables and the public and private data structures. In the beginning there is a series of declarations of constants that identify the integrated circuit’s hardware addresses, as regards both the RTCC part and the EEPROM one, in addition to the addresses of all the registers found. They are followed by a series of constants that are useful in order to set or reset the configuration bits found in the different registers. For each constant a comment has been thought: it explains how to take advantage of the constant that is shown. As an example, in order to activate the RTCC’s oscillator, you have to act on the “RTCSEC” register, and in particular on the most significant bit, by executing a boolean operation of the OR type (RTCSEC|OSCILLATOR_BIT_ON).
On the other hand, in order to reset such a bit, you will have to use a boolean operation of the AND type (RTCSEC & OSCILLATOR_BIT_OFF). In order to execute one of the previous operations, it is needed to read the register you’re interested in beforehand, to execute the desired boolean operation and finally to write the new register value.
A series of configuration constants – with the description of every single bit that composes them – follows. This section, if associated with a careful reading of the data-sheet, helps to fully understand what to do – and how – in order to configure the integrated circuit. The constants may be modified at leisure by the user, according to his needs; nothing stops from creating new ones. The last section concerns the EEPROM management; we would like to point out that the hardware address to be used in order to access it is a different one from the RTCC’s one.
After the declarations of constants we just explained, the declarations of all the public functions that are available to the end user (in addition to the declaration of all the variables that are needed for the management of the library) follow. In particular, it is worth to linger on the data structures that give us the possibility to act at bit level, for the configuration of the registers. We will soon see that it is possible to configure the registers in two ways: the first one involves the usage of specific dedicated functions and the other one involves the data structures’ configuration and consequent registers’ programming.

As an example, the data structure in Listing 1 allows to configure every single bit of the “CONTROL” register. Let’s suppose we want to enable the alarm 0, we will have to set the “Alarm0_Enable” bit with the following syntax:
mcp79410.ControlReg.Bit.Alarm0_Enable = 1;
Listing1
union ControlReg {
uint8_t ControlByte;
struct {
uint8_t SquareWaveFreqOutput :2;
uint8_t CoarseTrimEnable :1;
uint8_t ExtOscInput :1;
uint8_t Alarm0_Enable :1;
uint8_t Alarm1_Enable :1;
uint8_t SquareWaveOutputEnable :1;
uint8_t LogicLevelOutput :1;
} Bit;
} ControlReg;
In this way we only set a SRAM value in the ATmega328P microcontroller, found on the Arduino Uno R3 board. The next step is the one to recall a specific function, in order to write the piece of data in the specific memory location of the MCP79410 integrated circuit, for example by using the “WriteSingleReg” library function, to which a series of parameters must be given (among them, the address and the value of the register whose value we want to modify). The complete syntax will be:
mcp79410.WriteSingleReg(RTCC_HW_ADD, CONTROL_ADD, mcp79410.ControlReg.ControlByte);
In addition to the data structure we just illustrated, other and more articulated ones follow, they allow the configuration of the TimeKeeper registers, of the alarms and of the reading of the TimeStamps, PowerUp and PowerDown. For example, it is possible to see -in Listing 2– the data structure concerning the management of the TimeKeeper registers. As it may be noticed, for each RTCC configuration register (TimeKeeper), a structure of the “union” type is defined, it allows to act on each single bit of the register to be configured. Each “union” has been grouped in a “struct” data structure that is named “TimeKeeper”. With this approach we obtain a single “container” that it is possible to access for the configuration of each single bit (or for groups of bits) of each register. We will show a clarifying example: let’s suppose we have to set the “StartOsc” bit of the “RTCSEC” register. This bit is found in the “TimeKeeperSeconds” “union”, therefore in order to set it we will have to use the following syntax :
mcp79410.TimeKeeper.Second.SecBit.StartOsc = 1;
Listing2
typedef union TimeKeeperSecond {
uint8_t SecByte;
struct {
uint8_t SecOne :4;
uint8_t SecTen :3;
uint8_t StartOsc :1;
} SecBit;
} TimeKeeperSeconds;
typedef union TimeKeeperMinute {
uint8_t MinByte;
struct {
uint8_t MinOne :4;
uint8_t MinTen :3;
uint8_t Free :1;
} MinBit;
} TimeKeeperMinute;
typedef union TimeKeeperHour12 {
uint8_t Hour_12Byte;
struct {
uint8_t HrOne :4;
uint8_t HrTen :1;
uint8_t AmPm :1;
uint8_t _12_24 :1;
uint8_t Free :1;
} Hour_12Bit;
} TimeKeeperHour12;
typedef union TimeKeeperHour24 {
uint8_t Hour_24Byte;
struct {
uint8_t HrOne :4;
uint8_t HrTen :2;
uint8_t _12_24 :1;
uint8_t Free :1;
} Hour_24Bit;
} TimeKeeperHour24;
typedef union TimeKeeperWeekDay {
uint8_t WkDayByte;
struct {
uint8_t WkDay :3;
uint8_t VbatEn :1;
uint8_t PwrFail :1;
uint8_t OSCrun :1;
uint8_t Free :2;
} WkDayBit;
} TimeKeeperWeekDay;
typedef union TimeKeeperDate {
uint8_t DateByte;
struct {
uint8_t DateOne :4;
uint8_t DateTen :2;
uint8_t Free :2;
} DateBit;
} TimeKeeperDate;
typedef union TimeKeeperMonth {
uint8_t MonthByte;
struct {
uint8_t MonthOne :4;
uint8_t MonthTen :1;
uint8_t LeapYear :1;
uint8_t Free :2;
} MonthBit;
} TimeKeeperMonth;
typedef union TimeKeeperYear {
uint8_t YearByte;
struct {
uint8_t YearOne :4;
uint8_t YearTen :4;
} YearBit;
} TimeKeeperYear;
struct {
TimeKeeperSeconds Second;
TimeKeeperMinute Minute;
TimeKeeperHour12 Hour12;
TimeKeeperHour24 Hour24;
TimeKeeperWeekDay WeekDay;
TimeKeeperDate Date;
TimeKeeperMonth Month;
TimeKeeperYear Year;
} TimeKeeper;
Once this has been done, it is possible to recall the “WriteSingleReg” library function for the writing of a single register or – if you so prefer – you will have to configure all the above said registers beforehand and then to call the “WriteTimeKeeping” library function, to which we have to give only one parameter, so to indicate if the hour management is to be carried out in the 12h or 24h format. Therefore the syntax will be:
mcp79410.WriteTimeKeeping(0);
Now we will move on to the functions made available by the library. Eight functions for the general usage have been defined: three of them are needed in order to handle the single bits of a register, the remaining ones directly operate on the single bytes (or groups of them):
1) ToggleSingleBit(uint8_t ControlByte, uint8_t RegAdd, uint8_t Bit) 2) SetSingleBit(uint8_t ControlByte, uint8_t RegAdd, uint8_t Bit) 3) ResetSingleBit(uint8_t ControlByte, uint8_t RegAdd, uint8_t Bit) 4) WriteSingleReg(uint8_t ControlByte, uint8_t RegAdd, uint8_t RegData) 5) WriteArray(uint8_t ControlByte, uint8_t StartAdd, uint8_t Lenght) 6) ClearReg(uint8_t ControlByte, uint8_t RegAdd) 7) ReadSingleReg(uint8_t ControlByte, uint8_t RegAdd) 8) ReadArray(uint8_t ControlByte, uint8_t StartAdd, uint8_t Lenght)
The (1) function executes the “Toggle” function on the desired bit of the corresponding register. Therefore, if the indicated bit is “0”, it becomes “1” and vice versa. The parameters to be given are the “ControlByte” that identifies our RTCC’s hardware address (please refer to the MCP79410.h file for the hardware addresses assigned to the device), the “RegAdd” that is the register address on which you want to act, and finally the “Bit” parameter that identifies che bit you want to modify (from 0 to 7). The idea we just exposed may be extended to the following two functions, (2) and (3), that respectively execute a “Set” or a “Reset” as for the desired bit: the parameters to be given are the same. On the other hand, the following functions act on the corresponding bytes, for both writing and reading. As regards the writing (4) and reading (7) of a single byte, the parameters to be given to the function usually consist in the usual “ControlByte”, followed by the address to which to write or from which to read, “RegAdd” and, as regards only writing, the value that you want to write, that is “RegData”. The function (6), “ClearReg”, zeroes a register and needs the same parameters of the function (7). Finally, there are two functions for the writing (5) and the reading (8) of n consecutive values, they ask for the following parameters: “ControlByte”; the starting address, “StartAdd” and finally the number of bytes, “Lenght”. The functions (5) and (8) are based on a byte array named “DataArray” that has 16 as a length, which is more than enough for our needs. The functions that use the data array are useful in order to read or write the EEPROM or the SRAM of integrated circuit. When you have to write the EEPROM it is possible – at best – to send eight bytes at a time, since the device’s buffer has this maximum size.
Now, let’s move on to describe the most specialized functions, that have been purposely created so to best manage the MCP79410 integrated circuit:
1) GeneralPurposeOutputBit(uint8_t SetReset) 2) SquareWaveOutputBit(uint8_t EnableDisable) 3) Alarm1Bit(uint8_t EnableDisable) 4) Alarm0Bit(uint8_t EnableDisable) 5) ExternalOscillatorBit(uint8_t EnableDisable) 6) CoarseTrimModeBit(uint8_t EnableDisable) 7) SetOutputFrequencyBit(uint8_t OutputFreq)
The function (1) is needed in order to set the MFP output at logic “1” or at logic “0”; this may occur only in the case that both alarms have been disabled and that the output is not set for the purpose of reporting the oscillator’s clock frequency. The “SetReset” parameter, as suggested by the name, determines if the output has to be set or reset (“1” sets the output, vice versa for “0”). The (2) function enables/disables the possibility to report the clock frequency on the MFP line. The “EnableDisable” parameter enables or disables this function (“1” enables the report on the clock output, vice versa for “0”). Functions (3) and (4) are needed in order to enable the alarms and, as with the previous one, the only parameter to give is “EnableDisable”. Function (5) is needed in order to configure the integrated circuit, so to receive a clock signal on pin X1. This is useful if you do not want to use the 32.768Hz crystal on the pins X1 and X2. The only parameter to give is “EnableDisable” with the usual meaning.
Function (6) is needed in order to activate/deactivate the “Coarse Trim mode”, in combination with the “OSCTRIM” register, it allows a rough regulation of the time base for the management of the RTCC. The regulation is applied with a frequency of 128 Hz, and causing a remarkable influence on the time base. It is therefore preferable to leave this function disabled and, if needed, to regulate the time base by taking advantage of the OSCTRIM register only; of course this must be done by following a specific procedure (please see the Digital Trimming box).
The functions we presented until now modify a single bit at a time in the “CONTROL” register and to do so, they take advantage of the “SetSingleBit” and “ResetSingleBit” general functions that we previously described.
Function (7) is needed in order to select the frequency to be reported on the MFP pin; the selection loses meaning if the output is configured for the management of the alarms or as a general digital output.
Another series of functions will follow now: they are specialized for the configuration of some important operating features that are made available by the MCP79410 integrated circuit. These settings concern the TimeKeeper, the alarms and the TimeStamp functions:
1) StartOscillatorBit(uint8_t EnableDisable) 2) Hour12or24TimeFormatBit(uint8_t SetHourType) 3) AmPmBit(uint8_t SetAmPm) 4) VbatEnBit(uint8_t EnableDisable) 5) AlarmHour12or24TimeFormatBit(uint8_t SetHourType, uint8_t Alarm0_1) 6) AlarmAmPmBit(uint8_t SetAmPm, uint8_t Alarm0_1) 7) AlarmIntOutputPolarityBit(uint8_t SetReset, uint8_t Alarm0_1) 8) AlarmMaskBit(uint8_t Alarm0_1, uint8_t Mask) 9) ResetAlarmIntFlagBit(uint8_t Alarm0_1) 10) PowerHour12or24TimeFormatBit(uint8_t SetHourType, uint8_t PowerDownUp) 11) PowerAmPmBit(uint8_t SetAmPm, uint8_t PowerDownUp) 12) ResetPwFailBit(void)

Function (1) is essential since it is needed in order to activate or deactivate the oscillator. If the oscillator is switched off, there is no activity on the part of the RTCC and therefore no management concerning data, hour and related alarms. The “EnableDisable” parameter enables or disables the oscillator (“1” enables the oscillator, “0” disables it). The functions (2), (5) and (10) are needed in order to set the format of the hour, respectively for the timekeeper, for the alarms and the timestamp at the power-up/power-down. The hour may be represented in the 12h format, accompanied by the AM/PM indication, or in the 24h one; therefore, depending on the format we want to use, it is convenient to align all the three possible configurations, so to avoid mismatches. It doesn’t make much sense to have the timekeeper set to work in the 24h format, while the alarms are in the 12h format, unless we are dealing with peculiar applications. Function (2) needs only a parameter, “SetHourType”, in order to select one of the two formats available: “1” sets the format to 12h while “0” sets it to 24h. The functions (5) and (10) require an additional parameter in order to identify – respectively – to which alarm/timestamp to apply the parameter modification. Functions (3), (6) and (11) are needed in order to set, as regards the 12h format, if the time set refers to the morning or the afternoon (AM for the morning and PM for the afternoon). The parameter to be given is “SetAmPm”, if it’s “1” it sets PM, on the other hand if it’s “0” it sets AM. Functions (6) and (11) need an additional parameter, as already explained as for functions (5) and (10). Function (4) is needed in order to activate the management of the battery power supply, in the case the primary power source is missing; therefore in order to power the RTCC, the corresponding bit must be activated, and in order to do so the function we just introduced must be used: the parameter to be given is the usual “EnableDisable”.
Function (7) is needed in order to set the polarity of the MFP output (Table 1). The parameters to be given are two: the first one (“SetReset”) sets the polarity, that is to say “1” for the polarity with high logic level and “0” for the polarity with low logic level. The second parameter (“Alarm0_1”) is needed in order to select on which alarm to execute the modification of the polarity.
Function (8) is needed in order to set the masked comparison for the alarms. When the alarms are configured, in order to set the desired date and time for the interrupt generation, the masked comparison must also be set: it allows to decide on what to execute the test in order to trigger the alarm event. The available options are:
- comparison on seconds only;
- comparison on minutes only;
- comparison on the hour only (it takes the set format into account, that is to say either 12h or 24h);
- comparison on the day of the week only;
- comparison on the date only;
- complete comparison (the seconds, the minutes, the hours, the day of the week, the date and the month are compared).
Table2
![]()
When the interrupt of the n alarm is generated, the corresponding flag is set, and it must be manually zeroed by means of the code. It must never be left unresolved. In order to carry out the task it is possible to take advantage of the function (9), to which a single parameter must be given: it identifies the alarm 0 or 1.
The last one is function (12), which is used in order to reset the “PwFail” bit, that indicates that the main power source is missing and therefore that the timestamps at the power-up and at the power-down have been memorized. In other words, it saves the date and time of the moment in which the power went out and when it returned. Therefore, after having read the registers of the two timestamps, this flag must be compulsorily reset if you want that the registers are updated again at the next time the power goes out and returns.
It only remains to describe the last functions that, in combination with the previously described data structures, allow us to easily configure register blocks that are associated to the different functions made available by our RTCC:
1) WriteTimeKeeping(uint8_t Hour12or24Format) 2) ReadTimeKeeping(void) 3) WriteAlarmRegister(uint8_t Alarm0_1, uint8_t Hour12or24Format) 4) ReadAlarmRegister(uint8_t Alarm0_1) 5) WritePowerDownUpRegister(uint8_t PowerDownUp, uint8_t Hour12or24Format) 6) ReadPowerDownUpRegister(uint8_t PowerDownUp)
Function (1) is needed in order to program date and time of the RTCC, as we previously said even the activation bits of the oscillator and of the battery power supply’s management are included.
Therefore, by taking advantage of the specific data structure, the registers are configured with the correct values and then the integrated circuit is programmed by using function (1). The only parameter that is required is the selection of the hour format (12h or 24h). Function (2) is needed in order to read the configuration assigned to the TimeKeeper, the function reads the integrated circuit’s registers and transfers them in the specific data structure that may be used afterwards, for your own applications. The same may be said as for functions (3) and (4) that are respectively needed in order to configure the registers of the alarm and for reading their content. The two functions refer to their specific data structure. Since the possible alarms are two, the data structure is a structure array.
The overview is concluded with functions (5) and (6), used for the configuration and reading of the registers concerning the timestamp at the power-up and at the power-down. Even in this case, the functions are associated to a specific data structure, more accurately, to a structure array. Actually, the library considers two other functions concerning the management of the EEPROM memory. As already discussed, the integrated circuit has an internal 128 Byte EEPROM memory that may be rewritten, one 8 Byte block at a time. This memory may be freely written by the user, without restrictions. However, it is possible to decide to protect some sections of the EEPROM, so to preserve their content from overwriting. This may be done by configuring the “BP1” and “BP0” bits of the “STATUS” register, mapped at the 0xFF address. It is therefore possible to decide to protect the whole memory, or half memory (from 0x40 to 0x7F) or a quarter of memory (From 0x60 to 0x7F). The function dealing with the configuration of the “STATUS” register is:
Set_EEPROM_WriteProtection(uint8_t Section)
to which only a parameter must be given, that identifies which section to protect. The last function available is needed in order to unlock the protected EEPROM memory, that is to say, the one mapped at the addresses from 0xF0 to 0xF7, and to write a byte at the desired address. The function considers two parameters, that is to say the address on which to write and the piece of data to be written. The function is:
WriteProtected_EEPROM(uint8_t RegAdd, uint8_t RegData)
COMPLETE SKETCH
In order to study the functions made available by MCP79410, we wrote a sample sketch in which we show how to configure the TimeKeeper section and the alarms 0 and 1. The sketch is divided in six files, the main one being “MCP79410_AdvancedSettings.ino”, by double clicking on it, it is possible to start Arduino IDE and to open all the files associated to it. The sketch files are:
- MCP79410_AdvancedSettings The main file, it contains the functions “setup()” and “loop()”, that are typical of an Arduino sketch, as well as the variable declarations, the string constants, the time constants, the state machine declarations, etc;
- DigitalInput File for the management of the digital inputs, that is to say, the buttons P1, P2 and P3;
- DigitalOutput File for the management of the digital outputs (the D4 LED and the “ForceON” output);
- RTCC_Management File for the management of the MCP79410 integrated circuit and corresponding configuration;
- RTCC_Settings file for the programming of the MCP79410 integrated circuit’s TimeKeeper and of the alarms;
- TimersInt File for the management of the interrupts and timers.
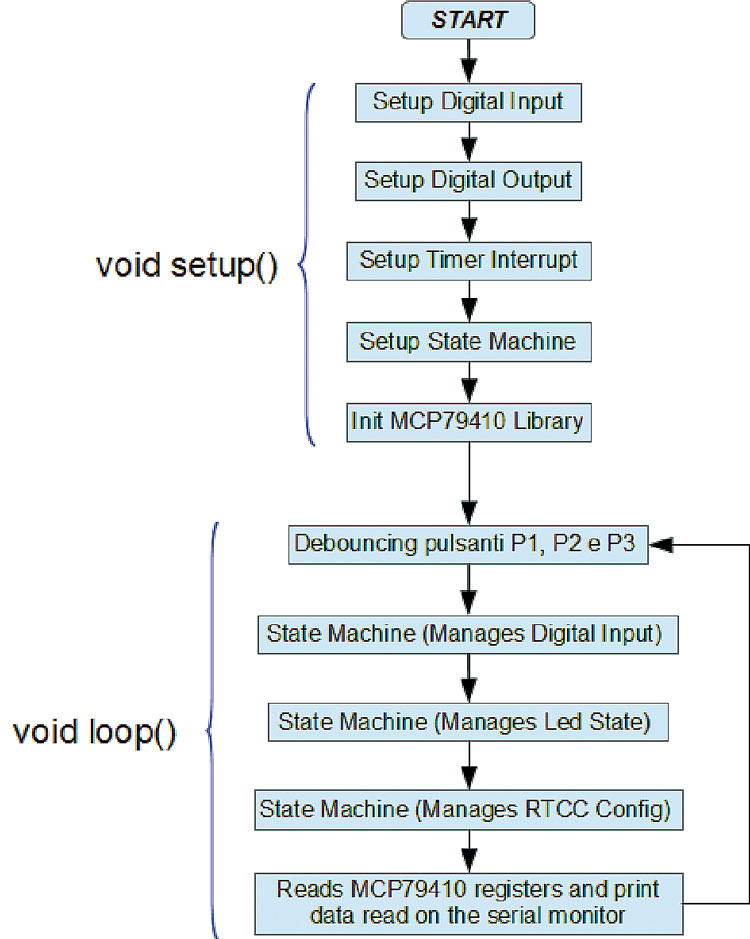
Thanks to the serial monitor (that may be activated from Arduino IDE), it is possible to give a series of string commands for the configuration of the Timekeeper and of the alarms 0 and 1. Moreover, during the “normal” functioning, that is to say, when the integrated circuit’s registers are not being configured, the system is programmed so to print some pieces of information to serial monitor: they concern the state of the Timekeeper and of the two alarms. The flow chart of our sketch is shown in figure: there is an initialization sequence that includes both the digital inputs and outputs, the state machines, the interrupts for the timebase and the initialization of the management library of the MCP79410 (this identifies the “setup()” function). The management functions follow, that is to say the reading and the debouncing of the digital inputs, the state machines and the reading function of the configuration assigned to MCP79410’s registers (this identifies the “loop()” function).
Now, let’s talk about how to configure the registers of our RTCC; first of all, it is needed to connect the Arduino Uno R3 board to the PC, via the USB connector, so to ensure a stable power source both to Arduino and to the shield; moreover, the serial and the corresponding monitor (for the sending of the commands from the PC to Arduino) are made available.
Once the serial monitor has been activated, it is possible to notice that the system executes a reading of the register configuration every fifteen seconds; figure shows the result. In the beginning, the system highlights that the RTCC’s oscillator is active and shows the current time and date. The configurations of the two alarms follow:
1) alarm state = Enabled/Disabled;
2) output polarity = high/low logic level;
3) Interrupt flag = it indicates if the alarm was triggered, depending on its configuration;
4) set hour = it shows the hour that has been configured for the alarm;
5) set date = it shows the date that has been set for the alarm (the year loses meaning as it’s irrelevant when managing the alarms);
6) mask = it shows the masked comparison for the generation of the interrupt, depending on the above said configuration.

At this stage we may decide to act in two different ways: the first one is to configure the time and date of the RTCC and therefore, if this is the first programming, you may consequently activate the oscillator and the management of the battery power supply; the second one is to configure alarms 0 and 1.
We will start by describing the configuration of time and date of the RTCC: first of all, you have to have the system start the configuration of date and hour, and in order to do so you have to press the P1 button for more than 2 seconds; LD4 will flash, so to indicate that the button pressure has been recognized. Once entered the configuration, LD4 flashes and a string will be printed to serial monitor, so to indicate that the system has entered the configuration of date and time. In order to exit this mode, please press again the P1 button, for more than 2 seconds; even in this case a string will indicate what has just been done.
The first step to carry out is the one to configure the date and the day of the week: for the purpose, you have to write the following command string, by taking advantage of the specific textbox of the serial monitor, and to click on the “return” button:
DateSet: 12/12/2015 – SAT
here, “DateSet:” is the command to carry out and “12/12/2015 – SAT” are the date and the day of the week. The day of the week are in English (MON, TUE, WED, THU, FRI, SAT, SUN).
In the case in which the command contains some errors, the system will return a warning string, that will invite the user to edit the command again.
The second step regards the hour configuration, therefore please type in the following command:
TimeSet: 14:30:10
Here, “TimeSet:” is the command to carry out and “14:30:10” is the time (in 24h format) to be set. If, on the other hand, you want to set the time but in the 12h format, you will have to write as follows:
TimeSet: 02:30:10 – PM
The system will recognize the desired format and will consequently configure the RTCC’s registers.
We will now move on to the configuration of the alarms 0 and 1: in order to activate the alarms configuration, please press the P2 button for more than two seconds, even in this case LD4 will flash and a specific string will be printed to monitor, be it for the activation or for the deactivation of the alarms setting.

As a first step you will have to configure the date, the mask and the polarity of the alarm 0 or 1. Let’s suppose we are working with the alarm 0:
DateSetAlarm(0): 12/12/2015 – SAT – SecondsMatch – LHL
here, “DateSetAlarm(0):” is the configuration command of the date for the alarm 0. The third parameter is the masked comparison, that may be set in order to work only on the seconds, only on the minutes, only on the hours, only on the days of the week, only on the date or so that the comparison will occur on all the parameters at the same time. In our example we chose that the comparison will happen only on the seconds: the other available ones are “MinutesMatch”, “HoursMatch”, “DayOfWeekMatch”, “DateMatch” and “AllMatch”. The fourth parameter is needed in order to select the output polarity, with “LHL” indicating a positive polarity, while “LLL” indicates a negative polarity. The second step is needed in order to configure the hour:
TimeSetAlarm(0): 14:30:10
here, “TimeSetAlarm(0):” is the configuration command for the hour of the alarm 0. In this case, for a matter of congruence with the hour configuration of the RTCC, the format is 24h. If you wanted to set the 12h format, the string would become:
TimeSetAlarm(0): 02:30:10 – PM
As for the RTCC configuration, the system automatically recognizes the desired format. Needless to say, if you wanted to set the alarm 1, the commands are identical to the previous ones, but with a reference to alarm 1; for example, DateSetAlarm(1):…… etc. If so desired, it is also possible to reset the alarms set, that is to say to completely delete their programming, thus disabling them. In order to do so, it is enough to give the following command:
ResetAlarm(0): or ResetAlarm(1):
On the other hand, if you simply wish to disable an alarm, please use:
DisableAlarm(0): or DisableAlarm(1):
In order to enable it, the command is:
EnableAlarm(0): or EnableAlarm(1):
All of the strings, be it the command or the warning ones, are memorized in the Flash memory of the Atmel microcontroller, so to save the SRAM memory; in fact, please keep in mind that all the times that you use the “println” function, with some text to be printed, it is loaded in the SRAM, thus occupying some precious space.
The above said commands are used in order to configure the data structures of which we talked about (during the description of the library and following programming of the registers); for such a reason, the different programmings are divided into two steps, of which it is always the second one to freeze the data in the RTCC’s registers. For example, during the configuration of date and time of the RTCC (TimeKeeper), once the correct data has been received, the system recalls the following programming function:
mcp79410.WriteTimeKeeping(0);
The parameter “0” indicates that the 24h format has been selected. On the other hand, during the alarms configuration the following ones will be used:
mcp79410.WriteAlarmRegister(AlarmIndex, 0); mcp79410.Alarm0Bit(1);
The first function saves the data in the registers as for alarm n, depending on the value of the “AlarmIndex” variable, 0 for alarm 0 and 1 for alarm 1, with 24h format; the second one activates alarm 0.
By opportunely configuring the two alarms, it is possible to reach a work situation in which alarm 0 forces the switching on and alarm 1 forces the switching off. We will now clarify what we just wrote: once the registers of the two alarms have been configured, you will have to disconnect the USB cable from the PC, thus turning off the power to the whole electronics, shield included. You will then have to supply power to the latter via the microUSB connector, and ensuring that the J1 jumper is in position 2-3. At this stage, the electronic parts that are downstream of the Q1 MOSFET will be powered only if the interrupt of alarm 0 is activated, by acting on the MFP output; in that case the sketch will detect that the interrupt flag of the alarm 0 went to logic “1” and therefore will force the “ForceOn” signal at high level, by keeping the power always turned on, and independently from the state of the MFP output. The system will therefore remain waiting for the event for the alarm 1 to be intercepted, once this happens the sketch will detect it and therefore will force the “ForceOn” signal at low level, by turning off all the electronics. All the times that the system detects that an alarm was triggered, it will deal with resetting the corresponding flag, by following a specific procedure. For the details, please see the sketch’s code, and two functions in particular:
void ResetAlarmFlag_0(void) void ResetAlarmFlag_1(void)
In order to see this perpetual trend of automatic switching on and off of the power source, it is sufficient to configure the two alarms, so to make a comparison only on the seconds (as pointed out before), and to opportunely set the seconds of the hour, for example: 12:10:10 for alarm 0 (Switching on) and 12:10:40 for alarm 1 (Switching off). In this way, the electronics is switched on for 30 seconds and switched off for just as many seconds.

Obviously, this is only a sample sketch, and in the actual cases you will want that the board is turned on at a certain hour of the day, so to be turned off at another one. Therefore it is possible to think to configure the comparison on the hours and not on the seconds, and to set – for example – the hour as follows: 08:00:00 for alarm 0 (Switching on) and 18:00:00 for alarm 1 (Switching off). In this way, every day of the year there would be a switching on and a switching off at the desired times. The possible available combinations are really a lot, and by opportunely modifying the sketch’s code it is possible to make everything more dynamic. In other words, it is the system to decide when the next switching on or switching off will take place, depending on the cases; it only depends on the wishes of the user, and on the implemented code. Our library and our electronics are only needed to give you the means to achieve your applications, as diverse as they may be.
PRACTICAL IMPLEMENTATION
We will now spend a few words on the subject of the shield’s construction: it requires a double sided printed circuit board. In practice, the shield is composed of SMD components only; the battery holder, the male and female strips and the buttons. As for the assembly, equip yourself with a 20W soldering iron having a very fine tip, flux paste, small pliers and a magnifying glass so to place the components and verify the weldings. The first components to be mounted are the Q1 MOSFET and U1, they are to be placed with the pins at the center of the respective pads, and to be weld one pin per side; all the passive components follow, the fuse, the crystal and the micro USB connector. Once this has been done, it is possible to move on to assembling the buttons and the battery holder, it is then the turn the side pin-strips (the ones for Arduino and the one for Raspberry Pi) are inserted and welded. As for the orientation of the polarized components, please refer yourself to the assembly plan that you will find in the previous pages. Please complete the weldings and verify – by means of the magnifying glass – that there are no short circuits, after that please insert the CR2032 battery.
From openstore
Shield RTC for Raspberry e Arduino
Raspberry Pi 3 Model B with Wi-Fi and Bluetooth

[…] Full documentation of the shield with its schematics and diagrams is available here. […]
[…] La documentación completa del escudo con sus esquemas y diagramas está disponible aquí. […]